- Oracle Database Code Generation
Oracle Database Code Generation
Code generation tools like Github CoPilot and Google Code Assistant are truly impressive when developing code to integrate with well documented APIs. Ask either of them to “write a python module to update a Google Sheet” and they are likely to generate a working example for you to refine. They are able to do this because Google has written extensive documentation for their Workspace APIs and these were included in the LLMs training data set.
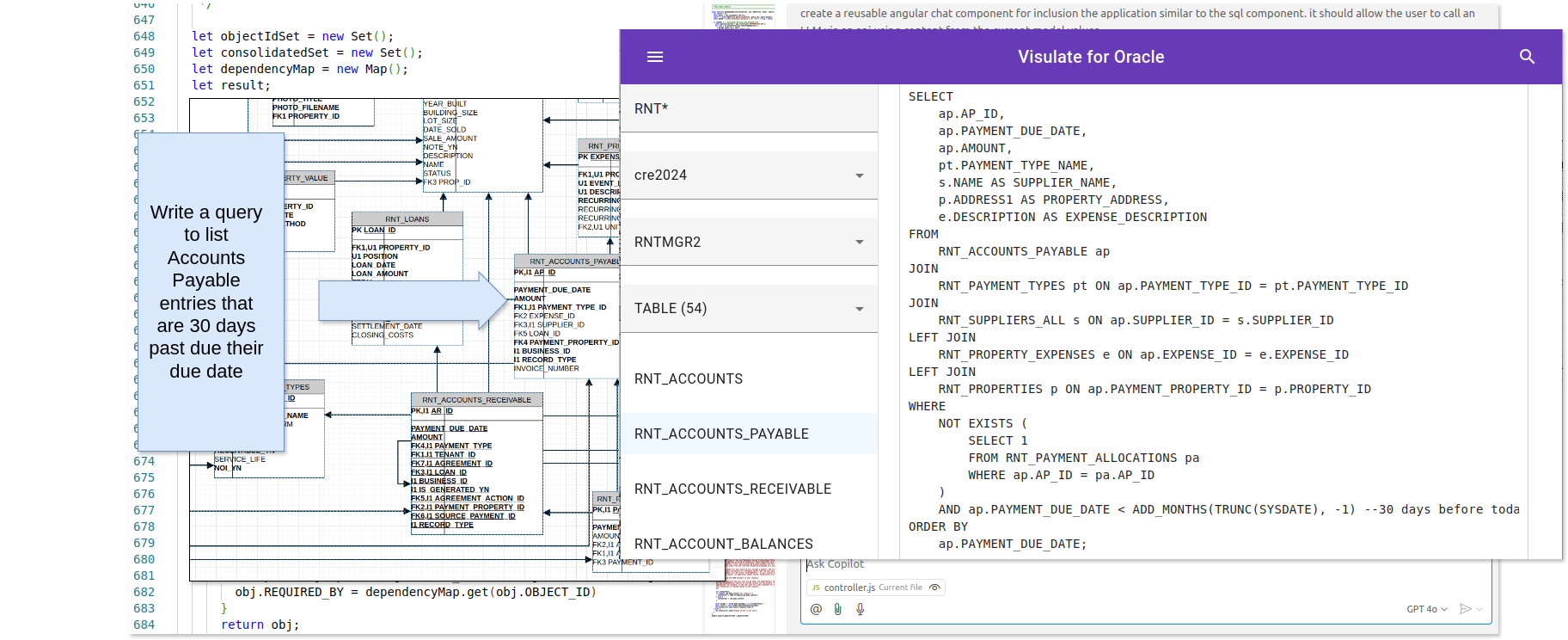
Try doing the same thing with a database query and the result is likely to be disappointing. For example, asking Github CoPilot to “write a SQL query to list Accounts Payable entries that are 30 days past their due date” is unlikely to produce a query that will run in your database. The dynamic and intricate nature of database schemas, coupled with the need for precise understanding of business logic, makes database code generation a complex task.
In this document, we’re going to explain how Visulate solves the problem of database code generation by leveraging Oracle’s data dictionary catalog to provide LLMs with a deep understanding of database schemas.
Challenges in Database Code Generation
When it comes to generating code for database queries, these tools often face significant challenges.
Understanding the Database Schema
- Table Structure and Column List: The foundation of any database query lies in understanding the structure of the tables involved. This includes identifying the correct column names, their data types, and their relationships with other columns within the same table or across different tables.
- Foreign Key Columns: Foreign keys establish relationships between tables, enabling data integrity and consistency. Generating accurate database code requires identifying these foreign key relationships and understanding how they impact the query’s joins and filters.
- Lookup Columns: Lookup columns often contain coded values that refer to descriptive text stored in separate lookup tables. To generate meaningful queries, the code generation tool must recognize these lookup columns and incorporate the necessary joins to retrieve the corresponding descriptive values.
- Dependencies and Stored Procedures: Databases often have complex dependencies between tables, views, and stored procedures. These dependencies can impact the execution of queries and must be considered during code generation to avoid errors or unexpected results.
The Need for Business Logic
Generating database code goes beyond simply understanding the schema. It requires interpreting the business logic behind the query. For instance, generating a report of unpaid invoices involves not only selecting the relevant invoice data but also applying appropriate filters based on payment status and due dates.
Current Limitations of LLMs
While LLMs have made significant strides in natural language processing, they still face limitations when it comes to database code generation. These limitations include:
- Lack of Deep Schema Understanding: LLMs may struggle to fully grasp the intricate relationships and dependencies within a database schema, leading to inaccurate or incomplete queries.
- Difficulty in Interpreting Business Logic: Translating natural language requests into precise database queries that align with the underlying business logic remains a challenge for LLMs.
- Limited Contextual Awareness: LLMs may not always have access to the full context of the database environment, such as custom data types, user-defined functions, or specific business rules, hindering their ability to generate accurate code.
The Path Forward
Overcoming these challenges requires a multi-faceted approach:
- Integration with Database Metadata: Providing LLMs with access to database metadata, such as data dictionaries can enhance their ability to generate accurate and contextually relevant code.
- User Feedback and Refinement: Incorporating user feedback loops can help LLMs learn from their mistakes and improve their code generation capabilities over time.
- Enhanced Training Data: LLMs need to be trained on a diverse range of database schemas and query patterns to improve their understanding of database structures and business logic.
Visulate supports each of these approaches.
The Path Forward using Visulate
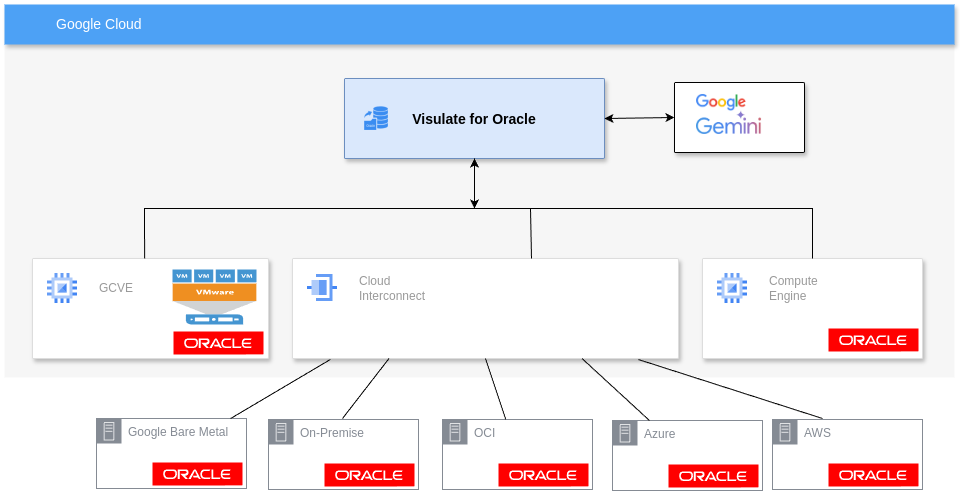
Visulate is an Oracle data dictionary browser and documentation tool. It provides a mechanism to catalog Oracle data dictionary content for registered databases. Visulate maintains a read-only Oracle database connection for each registration. These databases may be in multiple locations. For example, a Google Cloud deployment could document databases running in Google Compute Engine, GCVE or BMS as well as On-Premise, OCI, Azure and AWS.
Visulate’s Database Query Capabilities
Visulate includes a powerful query engine that allows users to examine the structure of each database in detail. For example, Visulate generates custom reports for each object type, such as tables, views, indexes, packages and package bodies.
One of the key strengths of Visulate’s query engine is its ability to understand the relationships between database objects. These could be tables with foreign key constraints, views that select from one or more tables or package bodies that reference a package spec. This enables Visulate to generate queries that accurately reflect the interconnectedness of data within the database.
Integration with Database Metadata
Visulate integrates this metadata with Google’s Gemini LLM to support code generation. For example, when a user navigates to a table in the UI Visulate creates a report describing the table’s structure. This report includes details of the tables columns, indexes, constraints and description along with its dependencies.
Visulate automatically assembles a JSON document with metadata for the current object and each dependent object every time a new database object is selected. This JSON is sent to the LLM as a grounding document when the user asks a question
The following diagram shows an example. The Accounts Payable table has foreign key columns to the Suppliers, Properties, Expenses, Loans and Payment Types tables. The Payment Allocations and Ledger Entries tables have foreign keys to it. There is also an Accounts Payable view which selects from the table and a number of stored procedures which reference it.
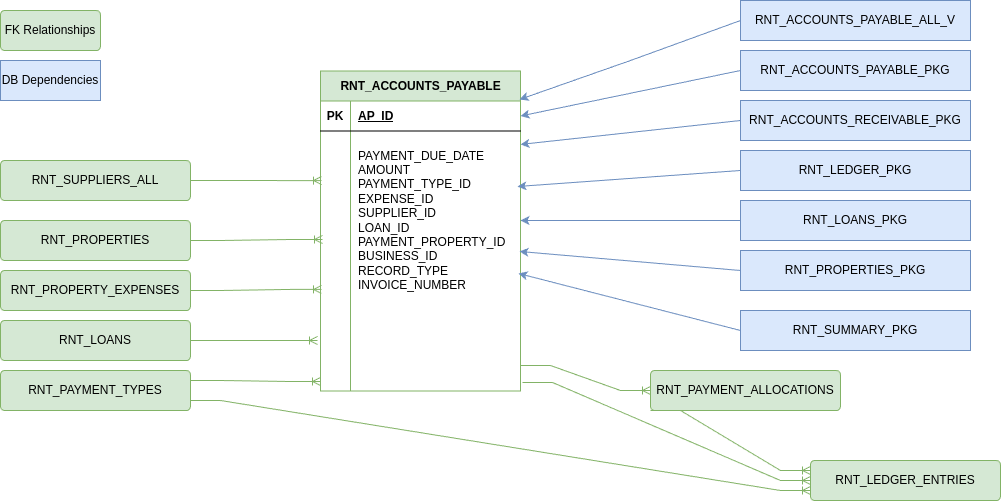
When the user asks Visulate to “write a SQL query to list Accounts Payable entries that are 30 days past their due date” the JSON document used for grounding includes details of each table shown on the diagram and each dependent object. This includes the columns, descriptions, index definitions and constraint definitions (PK, FK etc) for the table itself and each parent and child table. It also includes the source code for each stored procedure and text of every SQL statement that references the table.
This gives the LLM a 360 degree view of the database table. It can use this information to write SQL statements with multiple join conditions, generate client code for use outside the database (e.g. an accounts payable Java class or python module) or call a stored procedure to update a record.
User Feedback and Refinement
Visulate provides a chat interface to interact with the LLM. The chat context window acts as a real-time feedback loop. Every interaction, query, and response is documented within this window. This enables the user to provide immediate feedback on the LLM’s output.
If the generated SQL query is incorrect, the user can identify the error; if the response is ambiguous, the user can request clarification. This feedback is not simply received; it is actively incorporated into the LLM’s subsequent responses, leading to a progressively refined and accurate output.
The following is an unedited example of a chat session:
**You:**
Write a query to list Accounts Payable entries that are 30 days past due their due date
**Visulate:**
To list Accounts Payable entries that are 30 days past their due date, you can use the following SQL query:
SELECT
ap.AP\_ID,
ap.PAYMENT\_DUE\_DATE,
ap.AMOUNT,
pt.PAYMENT\_TYPE\_NAME,
s.NAME AS SUPPLIER\_NAME,
p.ADDRESS1 AS PROPERTY\_ADDRESS,
e.DESCRIPTION AS EXPENSE\_DESCRIPTION
FROM
RNT\_ACCOUNTS\_PAYABLE ap
JOIN
RNT\_PAYMENT\_TYPES pt ON ap.PAYMENT\_TYPE\_ID \= pt.PAYMENT\_TYPE\_ID
JOIN
RNT\_SUPPLIERS\_ALL s ON ap.SUPPLIER\_ID \= s.SUPPLIER\_ID
LEFT JOIN
RNT\_PROPERTY\_EXPENSES e ON ap.EXPENSE\_ID \= e.EXPENSE\_ID
LEFT JOIN
RNT\_PROPERTIES p ON ap.PAYMENT\_PROPERTY\_ID \= p.PROPERTY\_ID
WHERE
ap.PAYMENT\_DUE\_DATE \< ADD\_MONTHS(TRUNC(SYSDATE), \-1) \--30 days before today
ORDER BY
ap.PAYMENT\_DUE\_DATE;
This query joins the RNT\_ACCOUNTS\_PAYABLE table with RNT\_PAYMENT\_TYPES, RNT\_SUPPLIERS\_ALL, RNT\_PROPERTY\_EXPENSES, and RNT\_PROPERTIES tables to retrieve relevant information such as payment type, supplier name, property address, and expense description. The WHERE clause filters the results to include only entries where the PAYMENT\_DUE\_DATE is more than 30 days in the past. The ADD\_MONTHS function with a value of \-1 effectively subtracts one month from the current date, encompassing all entries past the 30-day threshold. The results are ordered by PAYMENT\_DUE\_DATE for easier review. Note the use of LEFT JOIN for RNT\_PROPERTY\_EXPENSES and RNT\_PROPERTIES to include entries even if there is no associated expense or property information.
**You:**
join to the payment allocations table to identify the payment date
**Visulate:**
To include the payment date from the RNT\_PAYMENT\_ALLOCATIONS table, you'll need to join RNT\_ACCOUNTS\_PAYABLE with RNT\_PAYMENT\_ALLOCATIONS using the AP\_ID column. Here's the modified SQL query:
SELECT
ap.AP\_ID,
ap.PAYMENT\_DUE\_DATE,
ap.AMOUNT,
pt.PAYMENT\_TYPE\_NAME,
s.NAME AS SUPPLIER\_NAME,
p.ADDRESS1 AS PROPERTY\_ADDRESS,
e.DESCRIPTION AS EXPENSE\_DESCRIPTION,
pa.PAYMENT\_DATE AS PAYMENT\_ALLOC\_DATE,
pa.AMOUNT AS PAYMENT\_ALLOC\_AMOUNT
FROM
RNT\_ACCOUNTS\_PAYABLE ap
JOIN
RNT\_PAYMENT\_TYPES pt ON ap.PAYMENT\_TYPE\_ID \= pt.PAYMENT\_TYPE\_ID
JOIN
RNT\_SUPPLIERS\_ALL s ON ap.SUPPLIER\_ID \= s.SUPPLIER\_ID
LEFT JOIN
RNT\_PROPERTY\_EXPENSES e ON ap.EXPENSE\_ID \= e.EXPENSE\_ID
LEFT JOIN
RNT\_PROPERTIES p ON ap.PAYMENT\_PROPERTY\_ID \= p.PROPERTY\_ID
LEFT JOIN
RNT\_PAYMENT\_ALLOCATIONS pa ON ap.AP\_ID \= pa.AP\_ID
WHERE
ap.PAYMENT\_DUE\_DATE \< ADD\_MONTHS(TRUNC(SYSDATE), \-1)
ORDER BY
ap.PAYMENT\_DUE\_DATE;
This updated query adds pa.PAYMENT\_DATE and pa.AMOUNT to the SELECT list, representing the allocation date and amount respectively. A LEFT JOIN is used on RNT\_PAYMENT\_ALLOCATIONS to ensure that even Accounts Payable entries without associated payments are included in the results. The PAYMENT\_ALLOC\_DATE will show when a payment was made against a given Accounts Payable entry. If multiple payments were made, multiple rows will be returned for that AP\_ID. PAYMENT\_ALLOC\_AMOUNT shows the amount of each payment allocation. Remember that an Accounts Payable entry may have zero, one or many payment allocations.
**You:**
only print rows where with no payment allocation records
**Visulate:**
To retrieve only the Accounts Payable entries without any associated payment allocation records, you can modify the previous query to use a NOT EXISTS clause. This clause checks for the absence of matching rows in the RNT\_PAYMENT\_ALLOCATIONS table for each AP\_ID.
Here's the updated SQL query:
SELECT
ap.AP\_ID,
ap.PAYMENT\_DUE\_DATE,
ap.AMOUNT,
pt.PAYMENT\_TYPE\_NAME,
s.NAME AS SUPPLIER\_NAME,
p.ADDRESS1 AS PROPERTY\_ADDRESS,
e.DESCRIPTION AS EXPENSE\_DESCRIPTION
FROM
RNT\_ACCOUNTS\_PAYABLE ap
JOIN
RNT\_PAYMENT\_TYPES pt ON ap.PAYMENT\_TYPE\_ID \= pt.PAYMENT\_TYPE\_ID
JOIN
RNT\_SUPPLIERS\_ALL s ON ap.SUPPLIER\_ID \= s.SUPPLIER\_ID
LEFT JOIN
RNT\_PROPERTY\_EXPENSES e ON ap.EXPENSE\_ID \= e.EXPENSE\_ID
LEFT JOIN
RNT\_PROPERTIES p ON ap.PAYMENT\_PROPERTY\_ID \= p.PROPERTY\_ID
WHERE
NOT EXISTS (
SELECT 1
FROM RNT\_PAYMENT\_ALLOCATIONS pa
WHERE ap.AP\_ID \= pa.AP\_ID
)
AND ap.PAYMENT\_DUE\_DATE \< ADD\_MONTHS(TRUNC(SYSDATE), \-1) \--30 days before today
ORDER BY
ap.PAYMENT\_DUE\_DATE;
This query efficiently filters out Accounts Payable entries with any associated payment allocation records, focusing solely on those where no payments have been applied. The NOT EXISTS subquery ensures that only those AP\_ID values which do not have a corresponding row in the RNT\_PAYMENT\_ALLOCATIONS table are returned. The other join conditions remain the same, retrieving comprehensive data for the Accounts Payable entries that meet the criteria. The AND condition filters results to only include entries with due dates more than 30 days in the past, ensuring the returned data aligns with the overdue accounts criteria.
**You:**
extend the query to show AR records that are 30 days past due
**Visulate:**
To extend the query to include Accounts Receivable (AR) records that are 30 days past due, we need to add a new UNION ALL clause to combine the results with the Accounts Payable query. The Accounts Receivable query will be similar in structure, using the RNT\_ACCOUNTS\_RECEIVABLE table and joining with relevant tables to retrieve necessary details.
Here's the combined SQL query:
SELECT
'AP' AS RECORD\_TYPE, \--added to distinguish AP and AR records
ap.AP\_ID,
ap.PAYMENT\_DUE\_DATE,
ap.AMOUNT,
pt.PAYMENT\_TYPE\_NAME,
s.NAME AS SUPPLIER\_NAME,
p.ADDRESS1 AS PROPERTY\_ADDRESS,
e.DESCRIPTION AS EXPENSE\_DESCRIPTION,
pa.PAYMENT\_DATE AS PAYMENT\_ALLOC\_DATE,
pa.AMOUNT AS PAYMENT\_ALLOC\_AMOUNT
FROM
RNT\_ACCOUNTS\_PAYABLE ap
JOIN
RNT\_PAYMENT\_TYPES pt ON ap.PAYMENT\_TYPE\_ID \= pt.PAYMENT\_TYPE\_ID
JOIN
RNT\_SUPPLIERS\_ALL s ON ap.SUPPLIER\_ID \= s.SUPPLIER\_ID
LEFT JOIN
RNT\_PROPERTY\_EXPENSES e ON ap.EXPENSE\_ID \= e.EXPENSE\_ID
LEFT JOIN
RNT\_PROPERTIES p ON ap.PAYMENT\_PROPERTY\_ID \= p.PROPERTY\_ID
LEFT JOIN
RNT\_PAYMENT\_ALLOCATIONS pa ON ap.AP\_ID \= pa.AP\_ID
WHERE
ap.PAYMENT\_DUE\_DATE \< ADD\_MONTHS(TRUNC(SYSDATE), \-1)
UNION ALL
SELECT
'AR' AS RECORD\_TYPE, \--added to distinguish AP and AR records
ar.AR\_ID,
ar.PAYMENT\_DUE\_DATE,
ar.AMOUNT,
pt.PAYMENT\_TYPE\_NAME,
t.TENANT\_ID,
p.ADDRESS1 AS PROPERTY\_ADDRESS,
NULL AS EXPENSE\_DESCRIPTION, \-- No expense description for AR
pa.PAYMENT\_DATE AS PAYMENT\_ALLOC\_DATE,
pa.AMOUNT AS PAYMENT\_ALLOC\_AMOUNT
FROM
RNT\_ACCOUNTS\_RECEIVABLE ar
JOIN
RNT\_PAYMENT\_TYPES pt ON ar.PAYMENT\_TYPE \= pt.PAYMENT\_TYPE\_ID
JOIN
RNT\_TENANT t ON ar.TENANT\_ID \= t.TENANT\_ID
LEFT JOIN
RNT\_PROPERTIES p ON ar.PAYMENT\_PROPERTY\_ID \= p.PROPERTY\_ID
LEFT JOIN
RNT\_PAYMENT\_ALLOCATIONS pa ON ar.AR\_ID \= pa.AR\_ID
WHERE
ar.PAYMENT\_DUE\_DATE \< ADD\_MONTHS(TRUNC(SYSDATE), \-1)
ORDER BY
RECORD\_TYPE, PAYMENT\_DUE\_DATE;
This combined query uses UNION ALL to append the Accounts Receivable results to the Accounts Payable results. A RECORD\_TYPE column is added to distinguish between the two record types. The WHERE clause in both parts remains consistent, filtering for records with PAYMENT\_DUE\_DATE older than 30 days. The final ORDER BY clause sorts the results by RECORD\_TYPE and then by PAYMENT\_DUE\_DATE. This provides a comprehensive view of both overdue Accounts Payable and Accounts Receivable records in a single, easily interpretable result set.
Enhanced Training Data
Future enhancements to Visulate could utilize the framework it provides to add natural language query capabilities for a complete database or collection of databases
Here’s how this enhancement could work:
- Schema Parsing: Visulate could incorporate a schema parsing component that analyzes the Oracle database structure ahead of time. This would involve extracting information about tables, columns, data types, constraints, and relationships.
- Knowledge Graph Creation: The parsed schema information could be used to construct a knowledge graph representing the database’s structure. This graph would capture the entities (tables), their attributes (columns), and the relationships between them.
- RAG Integration: The knowledge graph could then be integrated with a RAG-based reporting system. When a user asks a question, the system would use the knowledge graph to understand the context and retrieve relevant information from the database.
- Cross-Object Query Generation: By leveraging the knowledge graph, the RAG system could generate queries that span multiple tables, enabling it to answer questions that require a broader understanding of the database schema.
- Natural Language Responses: The RAG system could then generate natural language responses based on the retrieved information, providing users with insights that are easy to understand.
Benefits:
- Enhanced Reporting Capabilities: This enhancement would enable Visulate to provide more comprehensive and insightful reports, going beyond individual objects and answering questions that require a broader understanding of the database.
- Improved User Experience: Users could ask questions in natural language and receive answers that are easy to understand, without needing to know the underlying database structure.
- Increased Efficiency: Pre-parsing the schema and constructing a knowledge graph would improve the efficiency of query generation and response time.
Note: While Visulate currently only supports Oracle, this approach could be extended to other database systems in the future, further expanding its capabilities.
Copyright © Visulate LLC, 2019, 2025 Privacy Policy